

Getting your website fully optimized for search engines is essential to achieving higher rankings and driving organic traffic. A solid understanding of crawling and indexing lays the foundation for a successful SEO strategy.
This guide will explore mastering these processes, ensuring your website is primed for search engine visibility.
What is Crawling?
Crawling is the process where search engines, like Google, send bots (commonly called Googlebot) to discover new and updated pages on your website. These bots navigate your site’s links to gather content, which is then analyzed for indexing.
Example: Imagine a librarian visiting different shelves in a library to note down the titles and topics of all the books available. Similarly, a search engine bot “visits” pages on your website to understand their content and decide if they should be added to its database.
The Crawling Process
- Discovery: Search engine bots discover new URLs through links, sitemaps, or manual submissions.
- Access: Bots attempt to access and retrieve the content of the page.
- Evaluation: Once accessed, the bots analyze the page’s content and determine its relevance and quality.
- Decision: Depending on the evaluation, the page may or may not be indexed in the search engine database.
Now, let’s dive into actionable steps to enhance your website indexing and crawling.
1. Google Search Console Coverage Report Analysis
Google Search Console (GSC) provides a detailed indexing report, including URLs that are not indexed and the reasons why.
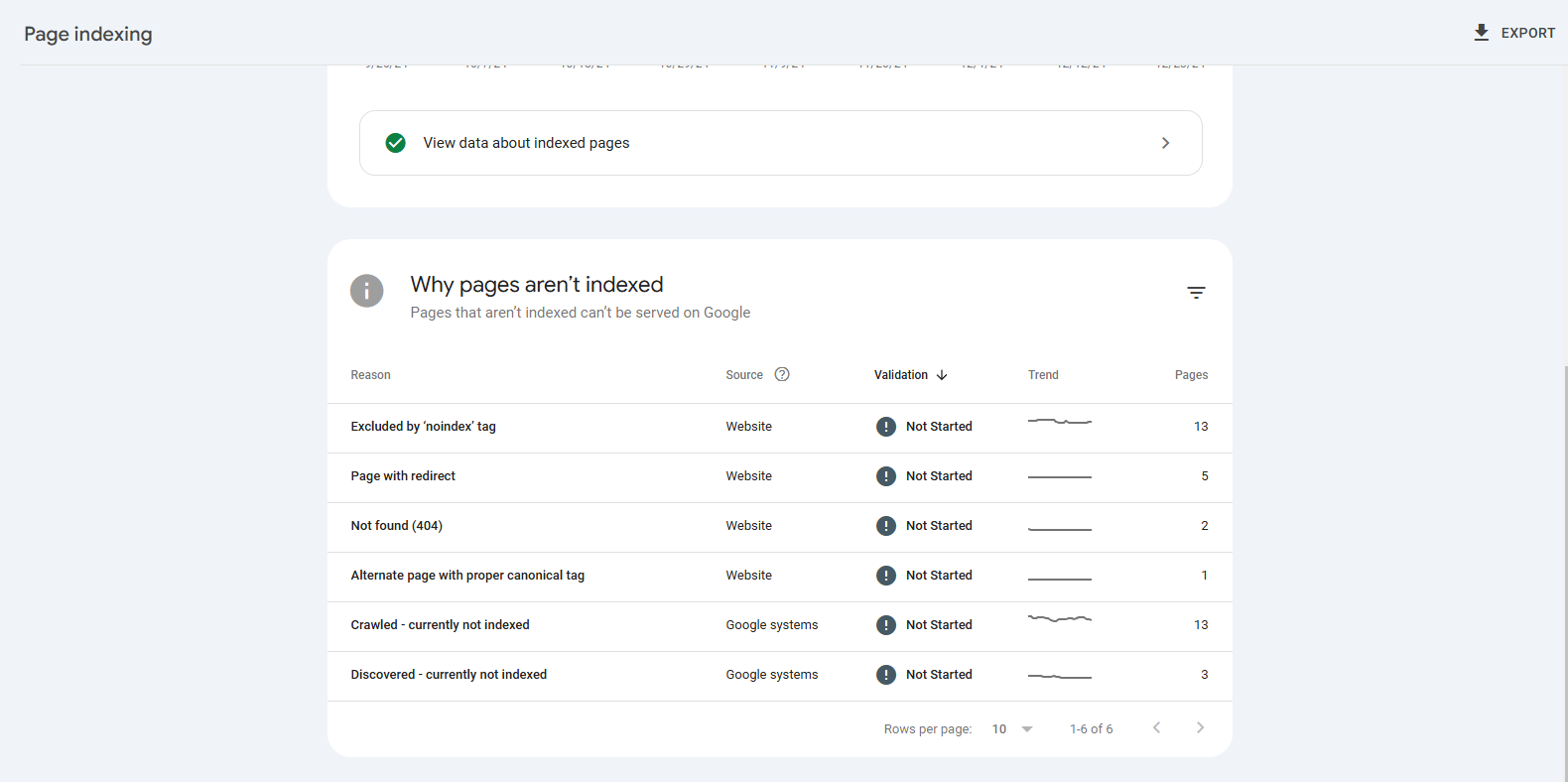
Use GSC to Identify:
- Pages Indexed Successfully
- Pages Not Indexed along with reasons
- Errors and Warnings
- Excluded Pages that need fixes
Focus Areas:
Discovered but Not Indexed:
This indicates that Google has found the URL but cannot crawl it. Possible reasons include:
- Blocking by robots.txt
- Unsupported resources like JavaScript files
- Server errors
Use GSC’s “Live Test” feature to troubleshoot and resolve these issues.
Read More – How do you check if Googlebot is crawling your whole page or not?
Crawled but Not Indexed:
Here, Google has crawled the page but deemed it unworthy of indexing. Common reasons:
- Low-quality or duplicate content
- Poor website quality
- Negative SEO practices
Address these issues by improving content quality and ensuring uniqueness. Check Google Helpful content guidelines.
2. Robots.txt Optimization
The robots.txt file directs search engine bots on which pages to crawl or avoid. Proper optimization ensures efficient crawling.
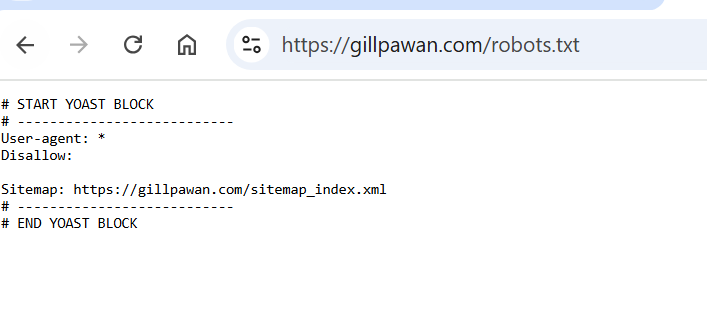
Best Practices: Allow Essential Pages
User-agent: *
Allow: /blog/
Block Unnecessary or Sensitive Pages:
User-agent: *
Disallow: /admin/
Ensure Clear Structure: Avoid blocking JavaScript or CSS files critical for rendering pages.
A well-structured robots.txt file helps prioritize important pages while keeping irrelevant ones from the search engine’s index.
3. XML Sitemaps
Sitemaps act as roadmaps for search engine bots, guiding them to your most important pages.
Ensure Smooth Crawling by:
- Creating XML sitemaps using tools like Screaming Frog or Yoast SEO.
- Keeping sitemaps updated with your latest pages.
- Submitting them to Google Search Console and Bing Webmaster Tools.
- This includes only the pages you want indexed, excluding those blocked by robots.txt.
4. Canonical Tag Audit
Canonical tags signal to search engines which version of a URL is preferred, preventing duplicate content issues.
Best Practices:
- Set canonical tags on similar pages to consolidate ranking signals. For example, in e-commerce websites, product pages often have multiple URLs due to filters or sorting options. Setting canonical tags ensures that only the primary product URL is indexed.
- Use the HTTPS version of your canonical tags. Example:
<link rel=”canonical” href=”https://www.example.com/preferred-page” />
Canonical tags ensure that search engines index the right version of your content, avoiding penalties for duplicates.
5. Index Bloat Check
Index bloat occurs when unnecessary or irrelevant pages are indexed, wasting the crawl budget and impacting SEO performance.
Reduce Crawl Inefficiencies by:
- De-indexing Thin or Irrelevant Pages: Remove pages with little to no value.
- Removing Outdated Content: Archive or delete pages that no longer serve a purpose.
- Auditing Regularly: Use tools like GSC and Screaming Frog to identify and address index bloat.
How Often to SEO Audit: Regular audits are recommended every 3-6 months, depending on the size of your website and the frequency of content updates.
More frequent audits may be necessary for large or dynamic websites. Index bloat occurs when unnecessary or irrelevant pages are indexed, wasting the crawl budget and impacting SEO performance.
6. Page load speed
Page load speed is critical for both user experience and search engine crawling efficiency. Slow-loading pages can result in higher bounce rates and reduced crawl budget allocation.
Improve Page Load Speed by:
- Optimizing Images: Compress images using tools like TinyPNG or ImageOptim.
- Minimizing JavaScript and CSS Files: Use minification tools to reduce file sizes.
- Leveraging Browser Caching: Ensure frequently used resources are cached to improve load times.
- Using a Content Delivery Network (CDN): Distribute content across multiple servers for faster delivery.
- Monitoring Performance: Use tools like Google PageSpeed Insights and GTmetrix to evaluate and improve page speed regularly.
7. Create High-Quality Content
Ensuring your web pages are worth indexing by search engines begins with creating high-quality content. Search engines prioritize content that delivers value, addresses user needs, and adheres to guidelines for helpfulness and relevance.
Key Elements of High-Quality Content:
- Relevance: Address the specific needs and queries of your target audience. Research popular questions or topics within your niche to ensure your content is valuable.
- Originality: Provide fresh insights unique perspectives, and avoid duplicating existing content. Strive to offer something that distinguishes your page from others.
- Structure: Make your content easy to read with clear headings, bullet points, and concise paragraphs. A well-structured layout improves user experience and engagement.
- Media Use: Enhance your content with images, videos, or infographics. Visual elements make your content engaging and easier to understand.
- SEO Optimization: Incorporate relevant keywords naturally within the content, titles, and headings. Ensure meta tags, descriptions, and alt text are well-crafted.
Guidelines for Helpful Content (Google’s Recommendations):
- Focus on People-First Content: Ensure your content is written primarily for humans rather than search engines. Address the questions and problems your audience cares about.
- Stay within Expertise: Share information where you have subject matter authority or experience. Provide trustworthy, well-researched, and fact-checked content.
- Avoid Misleading Practices: Don’t create content designed to attract search engines only, such as clickbait headlines with minimal value.
- Maintain a Unified Purpose: Focus on a clear, specific topic throughout your page. Avoid producing mixed or unrelated content in an attempt to target multiple audiences.
- Deliver Complete Answers: Make sure your content comprehensively covers the topic in a way that leaves users satisfied without needing to search further.
Conclusion
Mastering crawling and indexing is key to SEO success. By analyzing GSC reports, optimizing robots.txt, maintaining updated sitemaps, auditing canonical tags, and eliminating index bloat, you can ensure your website is easily discoverable and adequately represented in search engine results.
FAQs
What happens first, crawling or indexing?
Crawling happens first. The search engine bot must first crawl a page to understand its content and determine whether it should be indexed.
What is the next stage after crawling?
After crawling, the next stage is indexing. If the page meets specific criteria (e.g., no noindex directive, no crawling errors, valuable content), it gets stored in the search engine’s index.
What if I disallow the page in the robots.txt file? Can Google crawl it?
No, Googlebot cannot crawl the page. When you use a Disallow directive in the robots.txt file, you explicitly instruct search engine bots not to access that specific URL or directory. Googlebot respects the directive and will avoid crawling the page. However, it may still know about the page if it’s linked elsewhere, and the URL might appear in search results without any content snippet (since it wasn’t crawled)
What if I put no-index tag on my page? Can Googlebot still crawl it?
Yes, Googlebot can still crawl it. The noindex tag is placed within the HTML <meta> tag or the HTTP header, instructing search engines not to index the page. However, it does not prevent crawling. Googlebot can access and crawl the page to see the noindex directive, but it will exclude the page from the index, ensuring it doesn’t appear in search results.