

Googlebot plays a vital role in determining whether your webpage appears in search results. It’s not enough that your webpage looks perfect in your browser—you must ensure Googlebot can access and understand the content properly.
In this post, we’ll explore crawling, how it works, and how to verify if Googlebot is crawling your whole page.
What Is Crawling in SEO?
Crawling is the process by which search engines discover and retrieve the resources on your webpage. The search engine first identifies your content, then crawls all associated resources like images, JavaScript, and CSS files, making it eligible for indexing.
Crawling is a complex process. Googlebot retrieves a URL, makes an HTTP request to the server hosting it, and processes the response. This involves handling redirects, resolving errors, and passing page content to Google’s indexing.
Benefits of Crawling
Crawling is an essential step for your website to appear in search results. Without it, your content cannot be indexed, which means it’s invisible to users searching for relevant terms.
Ensuring Googlebot can access your entire webpage is crucial for proper indexing and ranking. Here are some benefits of crawling of your webpage –
- Enhanced Content Visibility: Crawling ensures that all parts of your webpage, including dynamic and multimedia elements, are indexed by Google and eligible to appear in search results. For example, if google crawl your product pages properly then it can appear in shopping tab in SERPs.
- Improved SEO Performance: Regular crawling helps search engines understand updates or changes to your content, boosting ranking potential.
- Detection of Technical Issues: Crawling can reveal errors like broken links, which can be fixed to improve user experience and SEO.
How to Ensure Googlebot Can Access Your Page
Just because you can access a page in your browser doesn’t mean Googlebot can. To confirm Googlebot’s accessibility, you need to examine your webpage the way Googlebot does.
One of the best tools for this is Google Search Console. This powerful tool provides insights into how Google crawls and indexes your site, allowing you to identify and fix potential issues.
You can check crawl stats in Google Search Console to see how google bot is crawling your website.
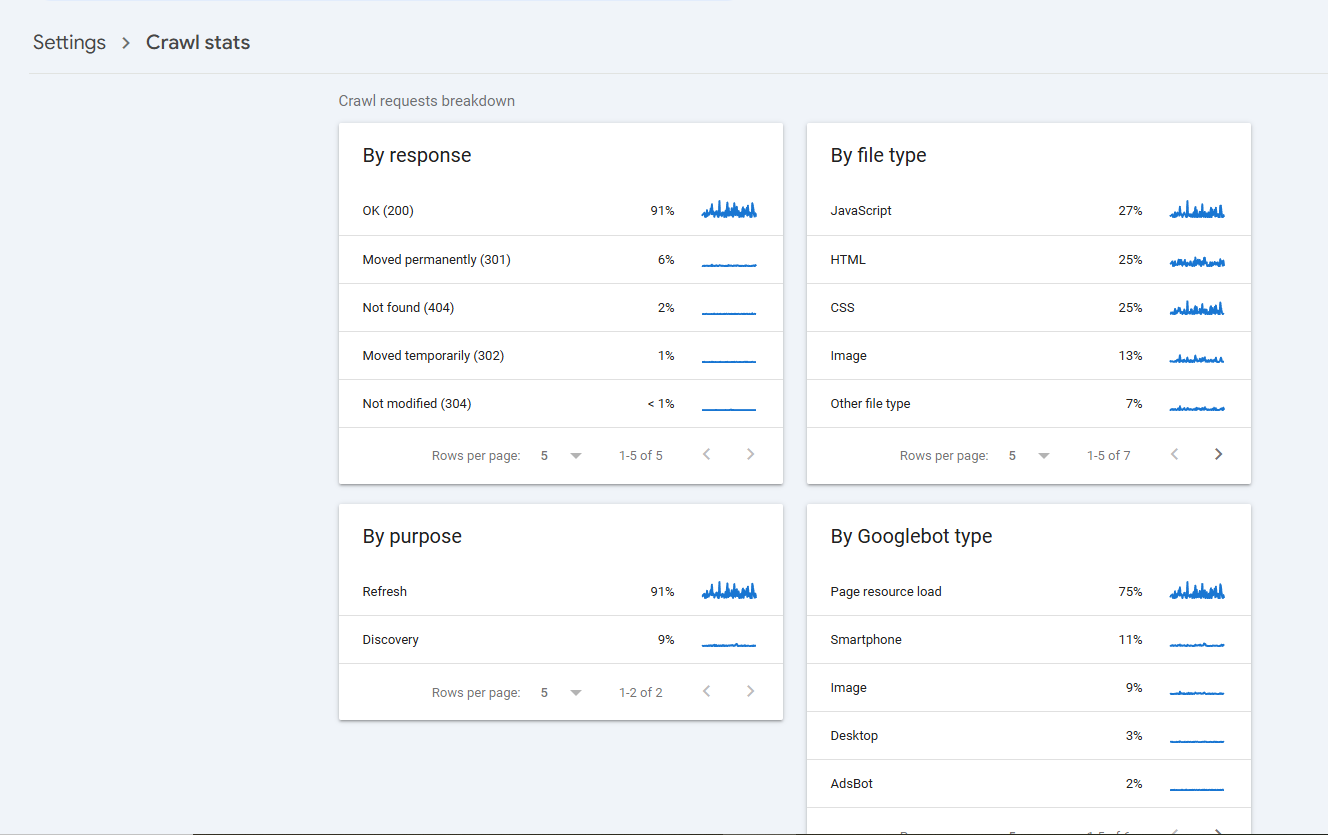
How to Check if Googlebot Is Crawling Your Whole WebPage
1. Avoid Using a Browser to Check Crawling Status
Simply opening your URL in a browser is not a reliable way to confirm if it has been crawled by Googlebot. Browsers and Googlebot handle resources differently, and what you see in your browser might not reflect Googlebot’s view.
2. Use the URL Inspection Tool in Google Search Console

The URL Inspection Tool in Google Search Console is invaluable for checking crawling status. Here’s how to use it:
- Perform a Live Test: Enter your URL in the inspection tool and press enter. The console will start retrieving data from search.
- Click on “Live Test”: This feature runs a real-time analysis of how Googlebot sees your page.
- View Rendered HTML: After the live test completes, the tool displays the rendered HTML. This reveals what Googlebot processed and whether there are any crawling issues.
- Check for Errors: If the page has errors like a “noindex” tag, a 404 error,5xx errors or blocked resources, they’ll be highlighted in the report. Resolve these issues promptly.
3. Verify Content in Rendered HTML
To ensure Googlebot has crawled your entire page:
- Search for specific content from different parts of the page in the rendered HTML.
- If the text is missing, Googlebot may have encountered issues crawling the page.
- Investigate further to address these issues.
5 Reasons Why Googlebot Cannot Crawl Your Page
If Googlebot fails to crawl your page, consider these common reasons:
- Blocked Resources: Resources like JavaScript, CSS, or images might be restricted in your robots.txt file.
- Server Errors: High server load or misconfigurations can prevent Googlebot from accessing your site.
- Noindex Tag: Pages with a “noindex” directive in the meta tags will not be indexed.
- 404 Errors: Broken links or deleted pages can result in Googlebot encountering 404 errors.
- Crawl Budget Limitations: Large websites with many pages might exceed their crawl budget.
How Can Screaming Frog Help Uncover Crawling Issues?
Screaming Frog is a powerful SEO tool that mimics Googlebot and provides detailed insights into crawling issues. Here’s how you can use it to uncover and resolve problems:
- Run a Crawl: Enter your website’s URL into Screaming Frog and start the crawl. It scans your site for all accessible pages and resources.
- Identify Broken Links: Screaming Frog highlights any 404 errors or broken links, allowing you to fix them promptly.

- Check Robots.txt Rules: Review which pages or resources are blocked by robots.txt to ensure that important content is accessible to search engines.
- Analyze Redirects: The tool displays all redirect chains and loops, which can waste crawl budget and impact SEO.
- Audit Meta Tags: Screaming Frog shows pages with missing or incorrect noindex and nofollow tags that could affect crawling and indexing.
- Review Page Depth: Pages buried too deep in the site hierarchy might not get crawled effectively; Screaming Frog helps you identify and optimize such pages.
- Inspect JavaScript Rendering: Use the tool’s rendering feature to check how JavaScript content is processed, ensuring that Googlebot can access it.
Conclusion
Crawling is a foundational step for a website’s visibility in search results. Using tools like Google Search Console ensures you stay on top of how Googlebot interacts with your site. Regularly monitor your site’s crawling status, address issues promptly, and optimize your resources to ensure a seamless experience for Googlebot. By doing so, you’ll maximize your chances of ranking high in search results.